Clean Code is straightforward and easy to understand. Writing Clean Code is a vital skill that all programmers should possess.
In the software development world, coding isn’t just about functionality. The code must also be maintainable and scalable. Writing Clean Code is an essential skill for every programmer. By writing Clean Code, you enhance your software not only for yourself but also for those who will maintain and develop it in the future.
1. What is Clean Code?
There’s no universally accepted official definition of Clean Code, as different programmers may have their own interpretations. Therefore, I will refer to a definition of Clean Code by Grady Booch:
“Clean Code is simple and direct. Clean Code reads like well-written prose. Clean Code never obscures the designer’s intent but rather is full of crisp abstractions and straightforward lines of control.” – Grady Booch
We can also simply define Clean Code as code that is easy to read, maintain, understand, and modify. Even as the codebase expands, it must still meet the requirements of functionality, security, and performance.
2. Understanding Code Smell
Contrary to Clean Code, we have Code Smell, which possesses characteristics that make the future maintenance and expansion of software more costly and risky.

2.1. What is Code Smell?
Code Smell refers to signs in a program’s source code that may indicate deeper, more complex issues. The term ‘Code Smell’ was introduced by Kent Beck on WardsWiki in the late 1990s and gained wider use after appearing in Martin Fowler’s book, ‘Refactoring: Improving the Design of Existing Code.’ Code Smell is the opposite of Clean Code, meaning that minimizing Code Smells is a way of adhering to Clean Code principles.
2.2. Characteristics of Code Smell
Code Smell isn’t a program error, nor does it prevent the program from running. Instead, it’s an indicator of design limitations that can slow down future development or increase the risk of future software errors. Code Smell can be identified through the following characteristics:
- Rigidity: It’s hard to change any part of the software. Even a small change in the program might require numerous modifications in many related areas.
- Fragility: Many components in the software can break due to a small change in the program.
- Immobility: It’s difficult or impossible to reuse a component in the program because it might cause uncontrollable errors or require too much effort.
- Overcomplication: Using overly complex algorithms, data structures, or solutions for problems, making it hard for others to understand. In simpler terms, it’s like ‘using a sledgehammer to crack a nut.’
- Unnecessary repetition: The same code fragments are unnecessarily repeated, leading to potential future issues if these sections are not uniformly modified during maintenance or further development.
- Obscurity: The reader struggles to understand the intent of the author, either due to confusing variable names or inconsistent steps in function execution relative to its name.
- Other specific characteristics: include excessively long functions, overly large classes, too many parameters for functions, comments that don’t aid in understanding the code, and redundant code segments that are not removed.

2.3. Why does Code Smell occur?
Code Smell can arise from several causes:
- Misunderstanding or ignorance of Clean Code principles: Programmers may not be aware of or correctly understand the principles of writing Clean Code.
- Unawareness of Code Smell indicators: Programmers might not recognize the signs of Code Smell.
- Copying and pasting code: Programmers might use code from other sources and paste it into their projects without thorough examination.
- Prioritizing deadlines over code quality: Programmers may think that spending time on writing Clean Code is unnecessary due to tight deadlines. They plan to refactor the code later, but often “later” means “never”.
3. Why write Clean Code?
Experienced programmers have likely encountered Code Smell, either creating it themselves or cleaning up after others. The common feeling when maintaining code with Code Smell is frustration, often leading to continuous questions about the origin of such messy code.

Perhaps the most disheartening aspect for a team dealing with Code Smell is the reduced productivity. It often leads to the creation of more problematic code sections, perpetuating a cycle of inefficiency. Initially, in a project, by passing Clean Code practices might seem to speed up development. However, as the project progresses, these unrefined code sections slow down the team due to the extra time needed to fix unrelated errors or refactor the smelly code.
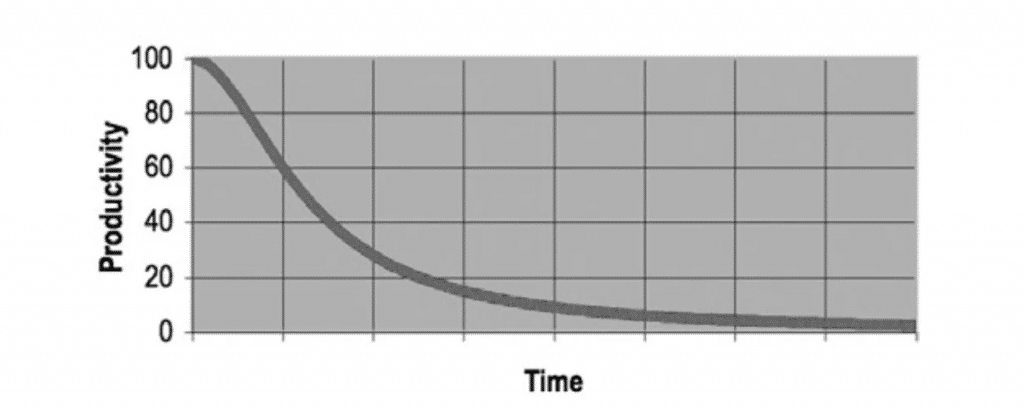
Here are the reasons why programmers need to write Clean Code:
- Ease of maintenance: Software maintenance involves fixing undiscovered errors from earlier development phases, upgrading features, and ensuring operational safety. Maintenance can take up to 65%-75% of the effort in a software’s lifecycle. Writing Clean Code makes it easier and faster for future maintainers to modify the software, thus enhancing productivity in later project stages.
- Facilitating collaboration: In a project, many individuals contribute, often leading to different coding styles that can be hard for others to understand. Writing Clean Code shows consideration for others’ ease of understanding and accessibility, rather than being comprehensible only to the author.
- Individual professionalism: A programmer’s skill level is reflected in various aspects, including the code they write. Reading another programmer’s code, one can gauge their professionalism through small details like commenting style, naming conventions, and the organization of the project structure.
- Team professionalism: The source code is the outcome of the team’s effort, and it can significantly reflect the professionalism in the software development process. Other factors like management skills, operational procedures, and team quality also play a role, but they are all, in some way, mirrored in the code produced by the programmers.
4. General principles for writing Clean Code

Writing Clean Code isn’t easy; it demands the right attitude, knowledge, understanding of code, and practical experience. However, we can start by adhering to some general principles:
- Follow common conventions: Teams usually have coding standards that everyone should follow for easier collaboration. If you find any convention unreasonable, discuss it with your team instead of breaking it alone.
- KISS (Keep It Simple, Stupid!): Programmers often use complex design patterns or algorithms without considering simpler solutions. Try to solve problems with straightforward, easy-to-understand approaches instead of rigidly applying complex coding techniques.
- Boy scout rule: Leave the code cleaner than you found it. When encountering Code Smell, replace it with Clean Code so future maintainers won’t encounter the same issues. While this requires extra effort, it reduces long-term maintenance costs and complexity.
- Find the root cause: Under time pressure, programmers might fix errors just to eliminate symptoms without addressing the root cause. This can lead to out-of-place code that only handles specific cases and disrupts the logic of a function, class, or even an entire package.
- DRY (Don’t Repeat Yourself): The core idea here is not to duplicate knowledge or business logic in the program. Code duplication is acceptable if the underlying knowledge or logic isn’t repeated. The goal is to have a single place for modifications. However, overzealous adherence to DRY can breach the KISS principle, so apply DRY judiciously.
5. Some basic principles of Clean Code in programming
5.1. Naming principles
There’s a popular saying among programmers: “There are only two hard things in Computer Science: cache invalidation and naming things” – Phil Karlton

You might see this as a joke, a truth, or both. Programmers of any level often struggle with naming variables, functions, classes, files, etc., in the most meaningful way possible. The following parts of this article will present some principles to help us name things, making the code “cleaner”.
5.1.1. Using purposeful variable names
Sometimes, programmers use abbreviations or certain letters to name variables. This can be useful when the variable’s scope is small and the number of variables is limited (1 or 2), as it doesn’t require the reader to spend effort remembering the meaning of those variables.

Picture 1: Naming variables with letters when their scope is limited
However, if the variable’s scope is broader, it’s advisable to name the variable with meaningful words to help the reader easily understand its purpose.

Picture 2: Naming variables with meaningful words for use in a wider scope
5.1.2. Creating clear distinctions
A bad habit in variable naming is using numerical suffixes for variables without giving them clear names that reflect their purpose. When variables share the same data type, it becomes difficult for the reader to understand their meaning without reading the related processing logic.
Picture 3: Using variable names with clear distinction in purpose
5.1.3. Using business-oriented naming
Variable names should be set according to the business context that the code segment is addressing, rather than using programming terminology for naming. For example, it’s preferable to name a variable ‘accounts’ instead of ‘accountArray‘ or ‘accountCollection‘.
5.1.4. Using business-oriented naming
Use a consistent word throughout the entire program to describe a particular action or concept. For instance, when writing a method to retrieve data in a class, you could use names like ‘getData‘, ‘retrieveData‘, ‘fetchData‘, etc. However, choose a single term to use across all classes (such as ‘fetchData‘) to avoid confusing the reader with multiple names serving the same purpose.
5.1.5. Naming methods and naming classes
There are two straightforward rules for naming methods and naming classes:
- Class names should be nouns or noun phrases: ‘Student‘, ‘ClassRoom‘, ‘School‘.
- Method names should be verbs or verb phrases: ‘countStudent‘, ‘showName‘.
5.1.6. Using names that are easy to pronounce and search
When combining multiple words into variable or function names, programmers sometimes use abbreviations, resulting in new, unpronounceable words like ‘MsgCtrl‘. Instead, it’s better to use the full name, like ‘MessageController‘.
Additionally, some programmers, unsure of what to name a variable, might use random letters like ‘asiiiiijjd‘ or ‘modyasasdbinadb‘, hoping to come back and rename them later with more suitable names. This practice should be avoided.
Names that are hard to pronounce are also hard to remember and search for. Another issue that makes searching difficult is using single or double letters for names, like ‘d‘, ‘e‘, ‘f‘. These letters often appear frequently in your code and can be challenging to distinguish.
5.2. Principles of function writing

A function should do one thing and do it well
5.2.1. Functions should be concise and do one thing only
Strive to limit the number of lines in a function to no more than 20. If that’s not feasible, ensure a function doesn’t exceed 100 lines, with each line having no more than 150 characters. This approach makes it easier for others to understand the function. (But it’s even better if one can guess the steps a function will execute just by looking at its signature.)
To keep a function’s content sufficiently small, break down larger functions into smaller ones that each handle a single task. This helps ensure that users don’t inadvertently cause side effects in other parts of the program. For instance, a function for retrieving data shouldn’t contain logic for resetting the value of a variable.
When splitting functions, adhere to the Single Level of Abstraction (SLA) principle. This means that the statements within a function should be at the same level of abstraction. After splitting, the content of the main function should only call these smaller functions, avoiding complex logic.
5.2.2. Use parameters reasonably
Initially, functions often start with few parameters. However, over time, to avoid altering existing logic, new parameters might be added, increasing their number. To reduce the number of parameters passed into a function, group them into a class and pass an object of that class instead of passing them individually.
Avoid using parameters to control a function’s logic. Instead, split the function into separate ones, each performing a specific task.
5.3. Principles of writing comments
5.3.1. Supplementing information for code
1. // regex for date with format yyyy-mm-dd
2. dateMatcher :=
regexp.Compile("^\d{4}\-(0[1-9]|1[012])\-(0[1-9]|[12][0-9]|3[01])$
3. ") The comment in the above example quickly provides information about the format of the declared pattern. With the addition of this comment, readers can grasp the logic of this command much faster than if they had to understand the pattern string passed to the ‘Compile’ function.
5.3.2. Providing additional information for the task
Comments can be used in various situations to inform the reader about tasks the author has completed or plans to address:
- Future tasks for a function or a class that need to be handled.
- Warnings about the use of a function that might produce undesirable side effects.
- Explanations for choosing one approach over another when multiple options are available.
- Clarifications for selecting specific values for constants and variables instead of other possible values
5.3.3. Avoid using comments when possible
In many cases, we can extract a piece of logic into a separate function and name it, rather than using comments to explain the purpose of that code. For example, a code snippet that checks a condition, as shown below, accompanied by a comment:
1. // check if the employee meets the criteria
2. if ((employee.flags & HOURLY_FLAG) &&
3. (employee.age > 65)) We can create a new function named isEligibleForFullBenefits and incorporate the logic from the if statement into this function. This approach not only eliminates the need for comments but also allows the logic of isEligibleForFullBenefits to be reused elsewhere.
Additionally, strive to name variables and use classes with suggestive and meaningful names so that readers can understand the code without needing comments.
5.3.4. Eliminate redundant comments
There are certain types of redundant comments that should be removed from our programs:
- Comments on code that is no longer used, or with the intention to reuse it later.
- Comments explaining function parameters that are already clear from the parameter’s name and data type, especially if the comment doesn’t provide any additional information.
- Comments that track changes made during each file edit. Such comments are unnecessary as version control systems like Git effectively record code changes.
5.4. Principles of error handling

5.4.1. Use exceptions instead of return codes
In languages that don’t support exceptions, one way to handle errors is by returning error codes. However, if programmers continue to use this approach in languages that do support exceptions, it can confuse readers who may struggle to quickly determine whether the returned value is an error or an actual value. Therefore, it’s recommended to throw exceptions when an error occurs instead of returning a specific error code.
5.4.2. Use Try-Catch-Finally at the beginning of a function
Using try-catch-finally implies the intention to perform a transaction, where the main actions are within the try block, while the catch block acts as a safety net to maintain system consistency even when errors occur. Therefore, placing try-catch-finally at the start of a function helps readers understand your intention right from the beginning.
5.4.3. Add contextual information to exceptions
When an error occurs, it’s beneficial to include useful contextual information about where and why the error happened. This allows programmers to easily trace back through the saved error information and quickly identify the root cause of the issue.
Some ways to provide error information include:
- Defining specific error classes, allowing readers to understand more about the context of the error based on the class name or its properties.
- Incorporating additional details into the error description string.
5.4.4. Avoid returning null
When a function can return null, the caller must check if the result is null before proceeding with further processing. This requirement leads to multiple checks in the code that can obscure the main intent and content of the code segment.
In cases where library functions might return null, consider writing your own wrapper functions around these. These wrappers can then either throw exceptions or return a special value instead of null.
5.4.5. Don’t ignore errors
Often, programmers unintentionally or deliberately leave errors unhandled, which can make it difficult or even impossible for maintainers to trace the source of the error. Errors should only be ignored when you are certain that they have no impact or potential risk to the program’s operation.
Therefore, always handle errors appropriately when they occur.
5.5. Principles of writing unit tests
5.5.1. Keep the logic simple
In software development, we write unit tests to ensure that the main program’s code functions correctly. But what guarantees the correctness of the unit tests themselves? Is it necessary to write tests for unit tests? If you continue to question this, you’ll realize there’s a potential for an infinite loop of testing.
Therefore, to minimize the likelihood of errors, the logic of unit tests should be kept simple. Here are some ways to achieve this:
- Organize steps in unit tests following the AAA pattern (Arrange, Act, Assert).
- Each test should contain only one assert statement.
- Each test should check only one specific case.
5.5.2. Express in business language
Unit tests are not only crucial for ensuring the main program’s code functions correctly, but they also serve as a form of documentation describing the program being developed. Therefore, use business language to express scenarios in unit tests, rather than programming jargon (like data types, design patterns, etc.).
5.5.3. The F.I.R.S.T principle
This principle is an acronym for five key attributes:
- Fast: Unit tests need to be quick so that developers can run numerous tests in a short period. If unit tests are slow, they tend to be run less frequently due to the reluctance to wait, potentially compromising the program’s reliability.
- Independent: Tests should not depend on each other; the success or failure of one test should not influence another. This independence is crucial for running tests in any order and executing them in parallel.
- Repeatable: Tests should be independent of external environments, allowing them to be run repeatedly in any setting without interruption. In other words, before running tests, don’t assume the presence of initial data in the system. Tests should not rely on services that might not be available, such as databases, files, or networks, and they shouldn’t leave data or impact other systems post-execution.
- Self-Validating: The result of a test should be binary, either passing or failing. After running a test, its success or failure should be immediately evident, rather than requiring manual comparison of values or returned information.
- Timely: Tests should be written at the right time, ideally just before the production code. Writing tests after the production code often makes it difficult to create suitable unit tests for the existing code. Developers typically use Test-Driven Development (TDD) to achieve this.”
6. Summary of Clean Code
Practicing the principles of Clean Code is crucial for any software development project. Writing Clean Code benefits individual programmers and the entire development team and the organization.
By adhering to Clean Code principles, programmers can enhance the overall quality of their programs, making the source code more understandable, easier to modify, and simpler to debug. Clean Code reduces technical debt, minimizes errors, and improves collaboration among team members.
In conclusion, Clean Code is an essential aspect of software development, profoundly impacting the efficiency, maintainability, and success of any project. It’s not just about writing code that works; it’s about writing code that is clear, understandable, and sustainable. The principles of Clean Code, including meaningful naming, concise functions, effective error handling, thoughtful commenting, and rigorous unit testing, are not just guidelines but necessities for creating robust, scalable, and collaborative software.
By embracing these principles, developers can avoid the pitfalls of complex, unmaintainable code, making their work not only easier to understand for themselves but also for others who might work on or use their code in the future. The ultimate goal of Clean Code is to enhance the quality of software, reduce technical debt, and foster an environment of continuous improvement and efficiency in the software development process. In essence, Clean Code is about writing code in a way that elevates it from mere functionality to a form of technical artistry.
To further enhance your knowledge and programming skills in Data & Programming, make sure to regularly follow high-quality posts on the zen8labs’ blog. Here, you’ll not only find valuable information about the latest technologies and industry trends but also witness a strong emphasis on writing Clean Code. This emphasis is not only evident in the articles but also in the software development process, where Clean Code principles are applied to create high-quality, maintainable, and scalable products


