
Scaling a web application transcends mere technical challenges—it’s a comprehensive journey that profoundly tests your mastery of architecture, user behaviour, and efficient resource management. This journey isn’t just about keeping your system running; it’s about anticipating growth and dynamically adapting to ensure that your infrastructure remains robust, scalable, and seamlessly efficient, no matter the demand.
In this blog, we give detailed information about developing a minimalist system designed for a single user. Guiding you through the process of the system, then finding ways to make it better and expand its capabilities to efficiently cater for millions of users.
The Starting Point: Simple Server Architecture
The beginning of your project is its infancy, housed on a single server. It’s simple: your database, application, and static content all reside on this lone warrior. While this setup suffices initially, as your user base expands, the cracks begin to show. Server response times lag, databases query slower, and the overall user experience starts to degrade.
Therefore, to meet the increasingly complex professional requirements, our system also needs to become more complicated, and this is where the components will be added to the system.
Second Point – what are the components?
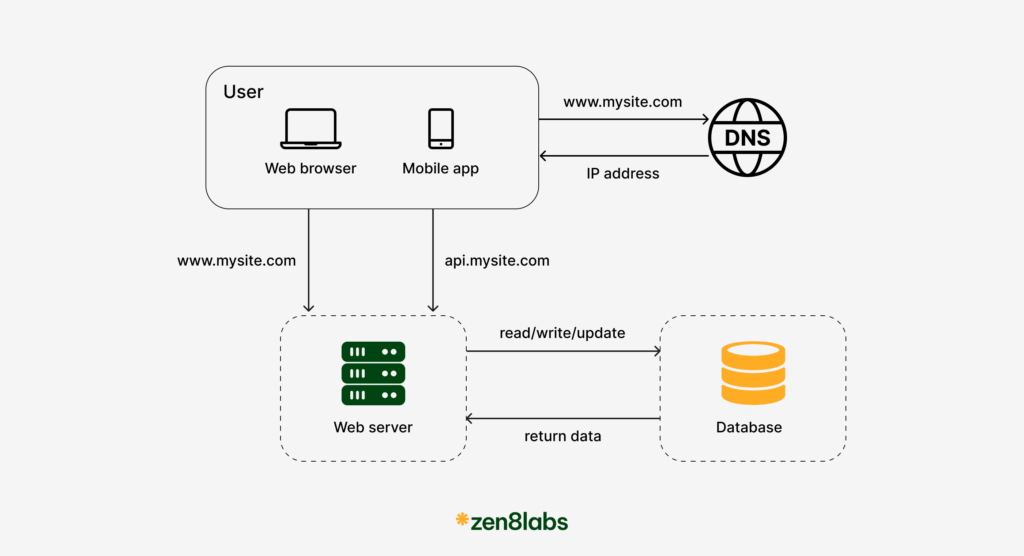
Domain Name System
The first and indispensable component in the systems we discuss here is the DNS.

DNS or Domain Name System is akin to the internet’s phonebook, translating user-friendly domain names into machine-friendly IP addresses. Here’s the typical flow:
- User Request: Accesses the site via a domain like api.mysite.com.
- DNS Lookup: Resolves the domain to an IP address.
- HTTP Request: Browser sends an HTTP request to the resolved IP.
- Server Response: Server fetches and returns the requested HTML or JSON content.
This process is crucial as it connects users to our server efficiently.
However, DNS is more than just resolution—it’s about routing users to the nearest server in their region, which reduces latency and improves load times.
Next, we want our server to be more interesting. This requires allowing clients to get/modify some resources such as create view tweets, messages, videos or data management. To do this, we need to have a database.
Databases
Databases play a central role in nearly every web application. They allow for the storage of user data, preferences, and other essential information that the application needs to function correctly.
We can explore the specifics of traditional relational databases and modern non-relational databases. Each type has its own set of strengths and challenges, which makes them suitable for different kinds of applications and scalability needs. I’ve added in additional information here about databases.
By understanding these databases’ roles and capabilities, you can make more informed decisions about which type best meets your application’s demands, ensuring optimal performance and scalability.
Load balancer
As your user base expands, the capabilities of a single server often become insufficient to handle the growing traffic. This calls for a robust solution to manage increased demands efficiently without sacrificing performance or uptime. The solution is adding additional web servers to serve all requests. However, simply increasing the number of servers is not enough; we also need a smart way to manage the traffic to them. That’s where a load balancer becomes essential
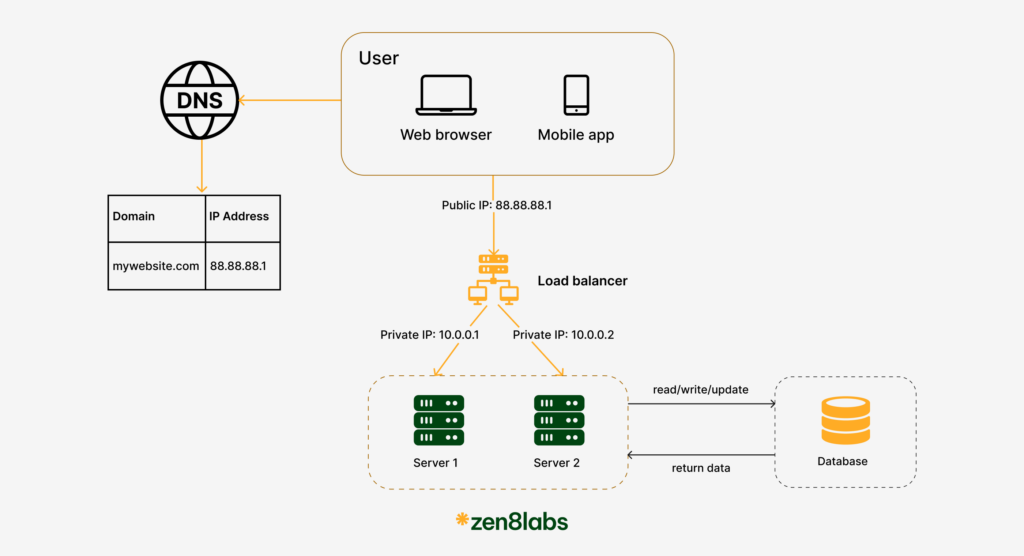
A load balancer evenly distributes incoming traffic among web servers that are defined in a load-balanced set. By evenly distributing the load, it ensures that no single server bears too much burden, thereby improving response times and enhancing overall service reliability. Imagine it as having multiple doors into a stadium; it facilitates smoother and faster entry, preventing any bottlenecks at a single entrance.
With load balancer, when one server goes offline, all the traffic will be routed to other servers. This prevents the website from going offline. We will also add a new healthy web server to the server pool to balance the load.
And when the website traffic grows rapidly, and current servers are not enough to handle the traffic, we only need to add more servers to the web server pool, and the load balancer automatically starts to handle it by sending requests to them.
Database replication
The current design has one database, so it does not support failover or redundancy. Besides that, there is a common pattern for many real-world applications: read requests are much higher than write requests.
So, Database replication is a popular technique to address those problems.
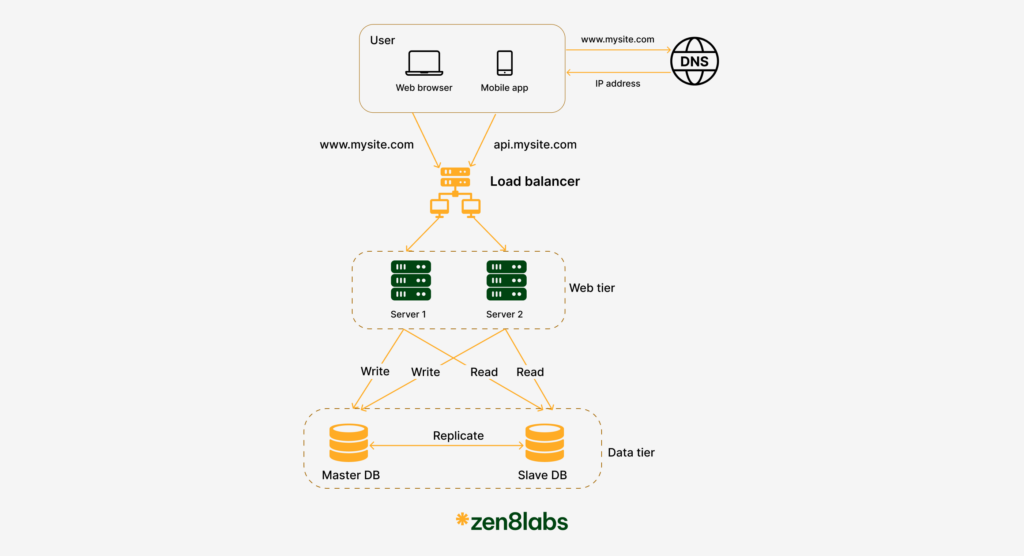
A Database replication is usually used with a master/slave relationship between the original (master) and the copies (slaves)
A master database generally only supports write operations
A slave database gets copies of the data from the master database and only supports read operations
All the data-modifying commands like insert, delete, or update must be sent to the master database. Most applications require a much higher ratio of reads to writes; thus, the number of slave databases in a system is usually larger than the number of master databases.
We talked about how a load balancer helped to improve system availability before. Now we also have the same question here: what if one of the databases goes offline?
- If only one slave database is available and it goes offline, read operations will be directed to the master database temporarily. As soon as the issue is found, a new slave database will replace the old one. In case multiple slave databases are available, read operations are redirected to other healthy slave databases. A new database server will replace the old one. The application performance is greatly affected by calling the database repeatedly and database query is slow due to disk operations. What is faster than a disk? RAM
- If the master database goes offline, a slave database will be promoted to be the new master. All the database operations will be temporarily executed on the new master database. A new slave database will replace the old one for data replication immediately.
In the fast-paced realm of web development, performance optimization is crucial. One of the most effective techniques for enhancing website speed and efficiency is caching
Cache
A cache is a temporary storage area that stores the result of expensive responses or frequently accessed data in memory so that subsequent requests are served more quickly
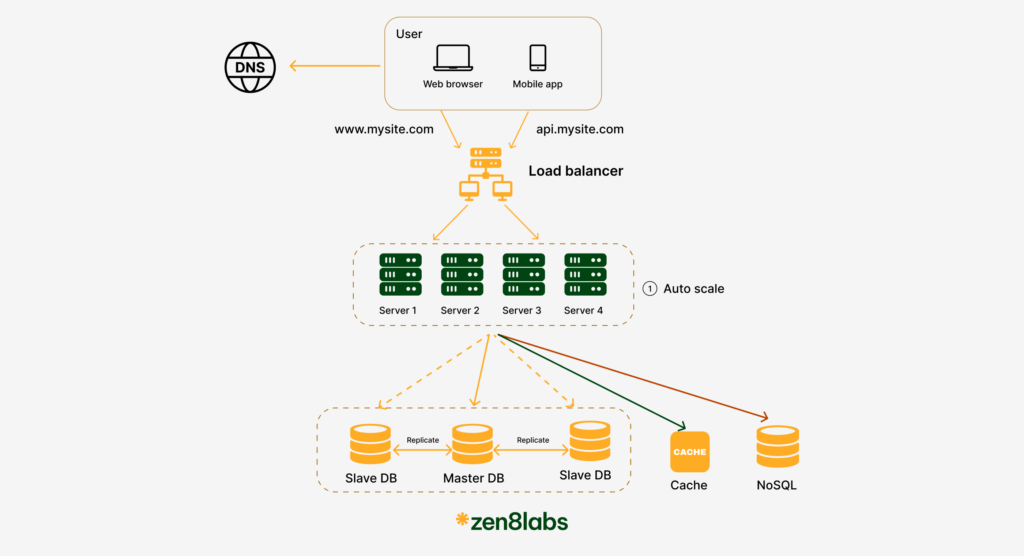
After receiving a request, a web server first checks if the cache has the available response. If it does, it sends data back to the client. If not, it queries the database and stores the response in cache and sends it back to the client.
This caching mechanism is pivotal for dynamic websites where requests can result in database queries or detailed computation. By storing the outcomes of these operations in cache, repeated operations are avoided, which conserves resources and speeds up web response times significantly.
Content Delivery Network
To further enhance the caching strategy, especially for geographically diverse user bases, employing a Content Delivery Network (CDN) can be incredibly effective.
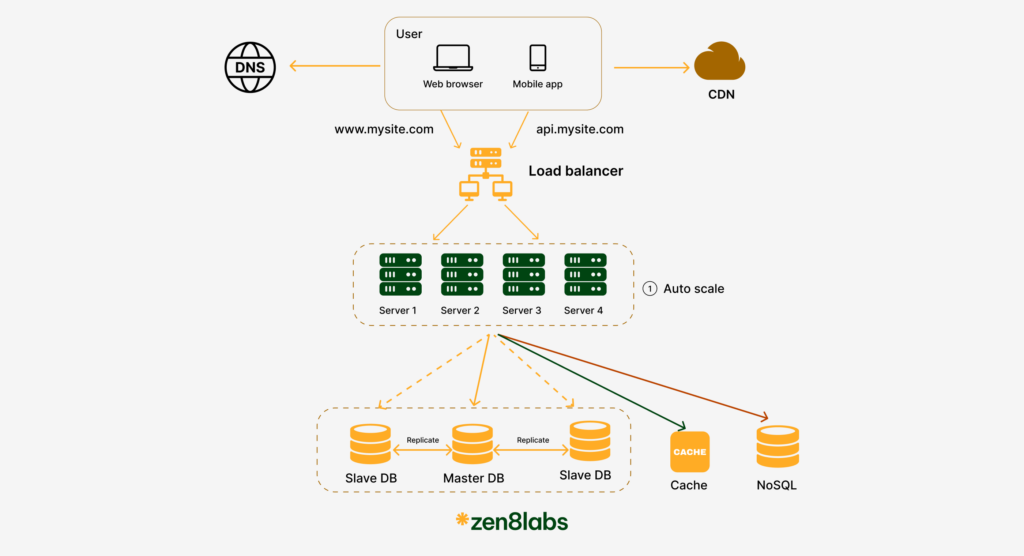
A CDN is a network of geographically dispersed servers used to deliver static content.
The CDN is the ideal solution for serving static content like images, videos, CSS, and JavaScript files. It helps in reducing the load on the web server and improves the response time for the users by delivering content from a nearby location.
When a user visits a website, a CDN server closest to the user will deliver static content. Intuitively, the further users are from CDN servers, the slower the website loads. For example, if CDN servers are set up in San Francisco, users in Los Angeles will get content faster than users in Europe. This is how CDN works at the high-level.
Message queues
Have you ever clicked on a submit order button only to land on an error page because the server was too busy processing other orders?
Performing many computations synchronously will affect critical path performance. So, we should do them asynchronously. To do this, we will use message queue or Pub/Sub model. Our web servers can publish the messages into relevant queue and downstream services can perform actions on the messages independently
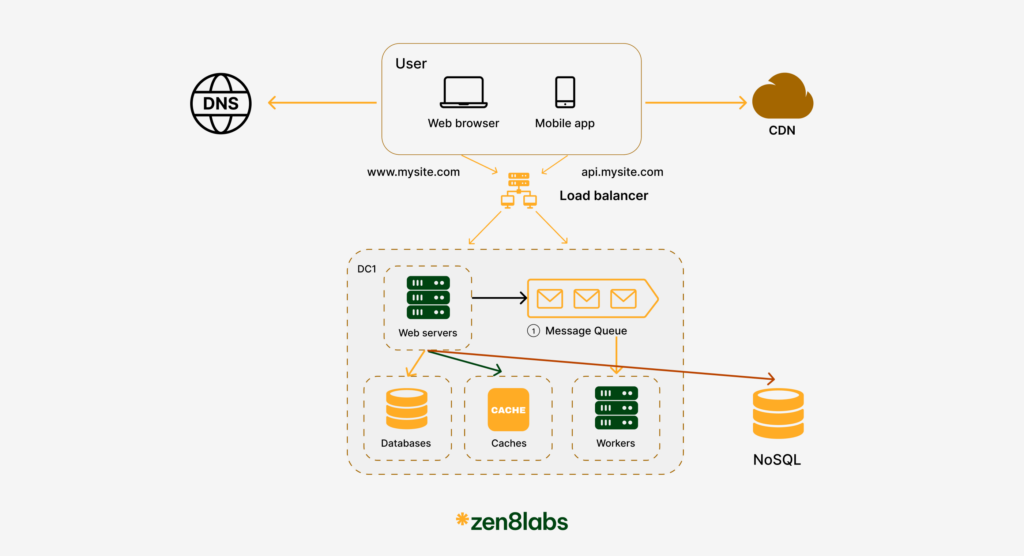
A message queue is a durable component, stored in memory, that supports asynchronous communication. It serves as a buffer and distributes asynchronous requests.
The basic architecture of a message queue is simple: input services (called producers/publishers) create messages, and publish them to a message queue, other services or servers (called consumers/subscribers) connect to the queue, and perform actions defined by the messages.
With the message queue, the producer can post a message to the queue when the consumer is unavailable to process it. The consumer can read messages from the queue when the producer is unavailable.
You can’t improve what you can’t measure.
Now our site has grown to serve a large business, investing in tools such as logging, metrics or automation support is essential
Logging, metrics, automation

Logging: Monitoring error logs helps to identify errors and problems in the system. We can monitor error logs at per server level or use tools to aggregate them to a centralized service for easy search and viewing.
Metrics: Collecting different types of metrics helps us to gain business insights and understand the health status of the system. Some of the following metrics are useful:
- Host level metrics: CPU, Memory, disk I/O, etc.
- Aggregated level metrics: for example, the performance of the entire database tier, cache tier, etc.
- Key business metrics: daily active users, retention, revenue, etc
Automation: When a system gets big and complex, we need to build or leverage automation tools to improve productivity. Continuous integration is a good practice, in which each code check-in is verified through automation, allowing teams to detect problems early. Besides, automating your build, test, deploy process, etc. could improve developer productivity significantly.
Final point – Conclusion
Scaling to one million users is an achievement, but it’s just the beginning. As you grow, continuously refine your architecture to handle more users, more data, and increasingly complex interactions. Keep learning, keep adapting, and stay ahead of the curve.
In my next couple of articles, I will delve deeper into each component and explore more specific optimization strategies to allow you to benefit from each blog. Stay tuned to the zen8labs blog.
Hieu Ha, Software Engineer


