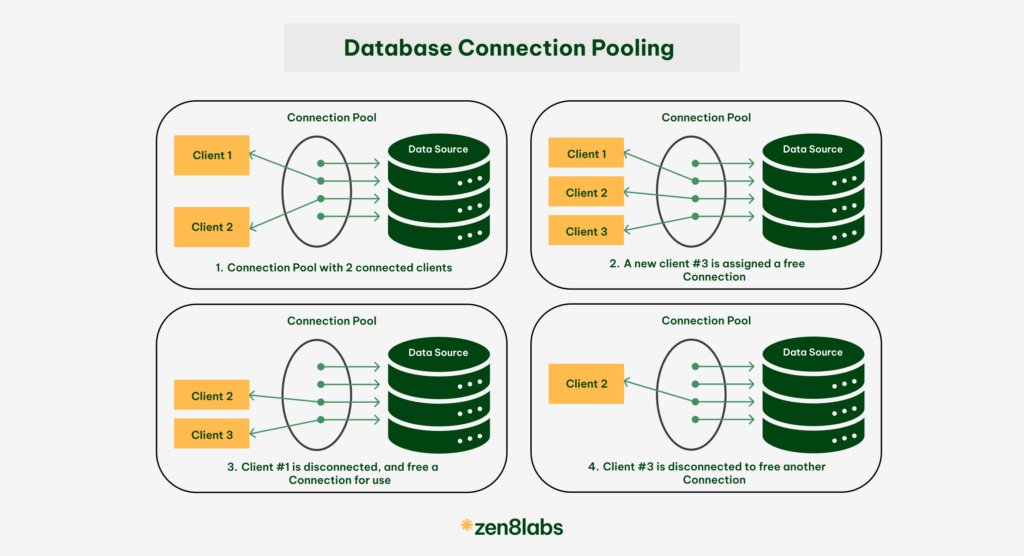
Introduction:
MySQL is a popular open-source relational database management system. MySQL is something we use at zen8labs, and it has become known for its performance, reliability, and ease of use. In this blog, we’ll explore its InnoDB Architecture, as well as the concepts of indexing and partitioning with examples to highlight their benefits and drawbacks.
InnoDB Architecture
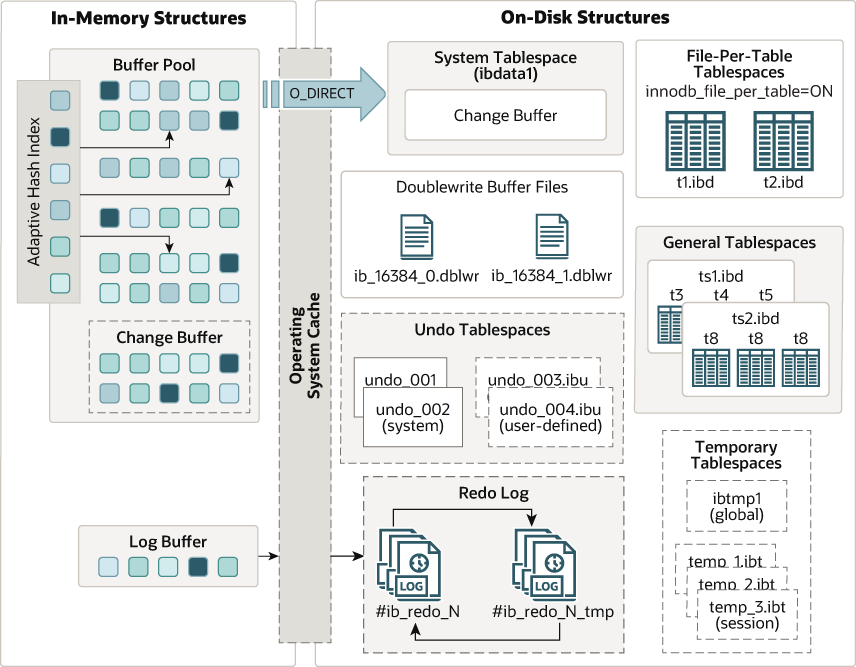
1. InnoDB In-memory structures
- Buffer pool
It is a memory area that caches table and index data, enabling frequently accessed data to be quickly retrieved from memory, thus speeding up processing. The buffer pool is divided into pages, each potentially holding multiple rows, and managed using a variation of the least recently used (LRU) algorithm to efficiently handle high-volume read operations. Effective use of the buffer pool is crucial for MySQL performance tuning.
- Change buffer
It stores changes to secondary index pages not in the buffer pool, delaying their merging to avoid inefficient random I/O. These changes are merged later when the pages are read into the buffer pool. This process reduces immediate disk access but can increase disk I/O during merging, which may slow down queries. The change buffer is part of the buffer pool in memory and the system tablespace on disk. It can be configured using the innodb_change_buffering variable and has limitations with descending index columns.
- Adaptive hash index
It enhances performance by creating hash indexes based on frequently accessed index pages, making data retrieval faster, like an in-memory database. Enabled by the innodb_adaptive_hash_index variable, it automatically builds hash indexes based on search patterns. While it speeds up queries for tables fitting in memory, it may cause contention under heavy workloads. It can be turned off if not beneficial, to avoid performance overhead. The feature is partitioned, with partitions controlled by the innodb_adaptive_hash_index_parts variable. Monitoring and adjustments can be done using the SHOW ENGINE INNODB STATUS output.
- Log buffer
It holds data to be written to log files on disk. Its size, set by the innodb_log_buffer_size variable, defaults to 16MB. A larger log buffer allows bigger transactions to complete without frequent disk writes, reducing disk I/O. The innodb_flush_log_at_trx_commit variable controls how and when this data is flushed to disk, while innodb_flush_log_at_timeout sets the flushing frequency.
2. InnoDB On-disk structures
- Tablespaces
It is storage areas where data and indexes are kept. There are three main types of tablespaces: the system tablespace, file-per-table tablespaces, and general tablespaces. The system tablespace is the default storage area that holds system information and user data. File-per-table tablespaces give each table its own file (with a ‘.ibd’ extension), improving performance and making management easier. General tablespaces allow multiple tables to share the same storage file. Using tablespaces helps with better data organization, improves performance, and simplifies backup and restore processes. File-per-table tablespaces are enabled by default in MySQL, and general tablespaces can be created using the CREATE TABLESPACE command. This setup allows efficient data management and maintenance.
- Doublewrite buffer
It is a feature designed to prevent data corruption during crashes. It works by first writing data pages to a special buffer in the system tablespace before writing them to the actual data files on disk. This two-step process ensures data integrity, as InnoDB can use the buffer to recover data if a crash occurs during the write process. The doublewrite buffer is enabled by default in MySQL and is crucial for maintaining data reliability.
- Redo log
It ensures data durability and aids in crash recovery. It records all changes made to the database, which are first written into the redo log before being applied to the data pages. This process allows InnoDB to recover and replay these changes in case of a crash. The redo log consists of a redo log buffer (temporary storage in memory) and redo log files (permanent storage on disk). The redo log buffer size is controlled by the innodb_log_buffer_size variable. This system is essential for maintaining database reliability and ensuring data can be recovered after a crash.
- Undo log
It enables transaction rollback and supports consistent reads. It records original data before any changes are made by a transaction, allowing the database to revert to its previous state if needed. This log is crucial for maintaining data integrity and multi-version concurrency control (MVCC), ensuring that transactions are isolated and can see consistent snapshots of the data. Undo logs are automatically managed and periodically purged when no longer needed.
Indexes in MySQL
Indexes are special data structures that improve the speed of data retrieval operations on a database table at the cost of additional storage space and slower write operations.
Example without index
Consider a table authors with the columns id, first_name, last_name, email, birthdate and added. Without an index, a query like this:

will require a full table scan, meaning every row in the table is checked to find matches, which can be slow for large tables.
Example with index
By adding an index on the name column and the same query:

will be much faster because MySQL can quickly locate the data using the index.
Advantages and disadvantages of indexes
Advantages:
- Speed: Dramatically faster read operations for indexed columns.
- Efficiency: More efficient query processing, especially for large datasets.
Disadvantages:
- Storage: Requires additional storage space.
- Write Performance: Slower write operations (INSERT, UPDATE, DELETE) because the index must be updated.
Partitioning in MySQL
Partitioning involves dividing a large table into smaller, more manageable pieces, which can improve performance and simplify maintenance.
Example without partitioning
A large authors_partition table storing thousands of records can become slow to query and manage. A query to retrieve last month’s sales might scan the entire table:

will show that the entire table is being scanned.
Example with partitioning
By partitioning the authors_partition table by date and the same query:
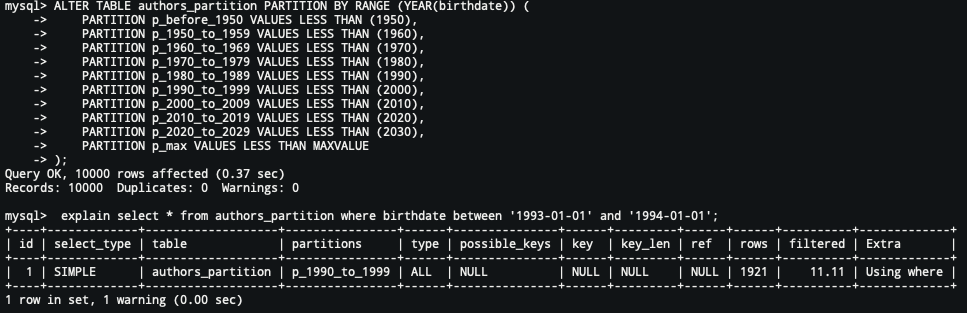
Advantages and disadvantages of partitioning
Advantages:
- Performance: Improved query performance by scanning only relevant partitions.
- Maintenance: Easier management of large datasets, such as archiving old data.
Disadvantages:
- Complexity: Added complexity in schema design and management.
- Overhead: Potential overhead in managing partitions, especially if not properly optimized.
Conclusion
MySQL’s architecture, with its client-server model, multiple storage engines, and efficient query processing, makes it a powerful database management system. Indexing and partitioning are essential features that can significantly improve performance but come with their own set of trade-offs. Using the EXPLAIN statement can help you understand and optimize your queries, leading to better performance and scalability for your MySQL databases. If databases and all thing IT interest you, you have to read the zen8labs blog.
Nguy Minh Hien, Software engineer